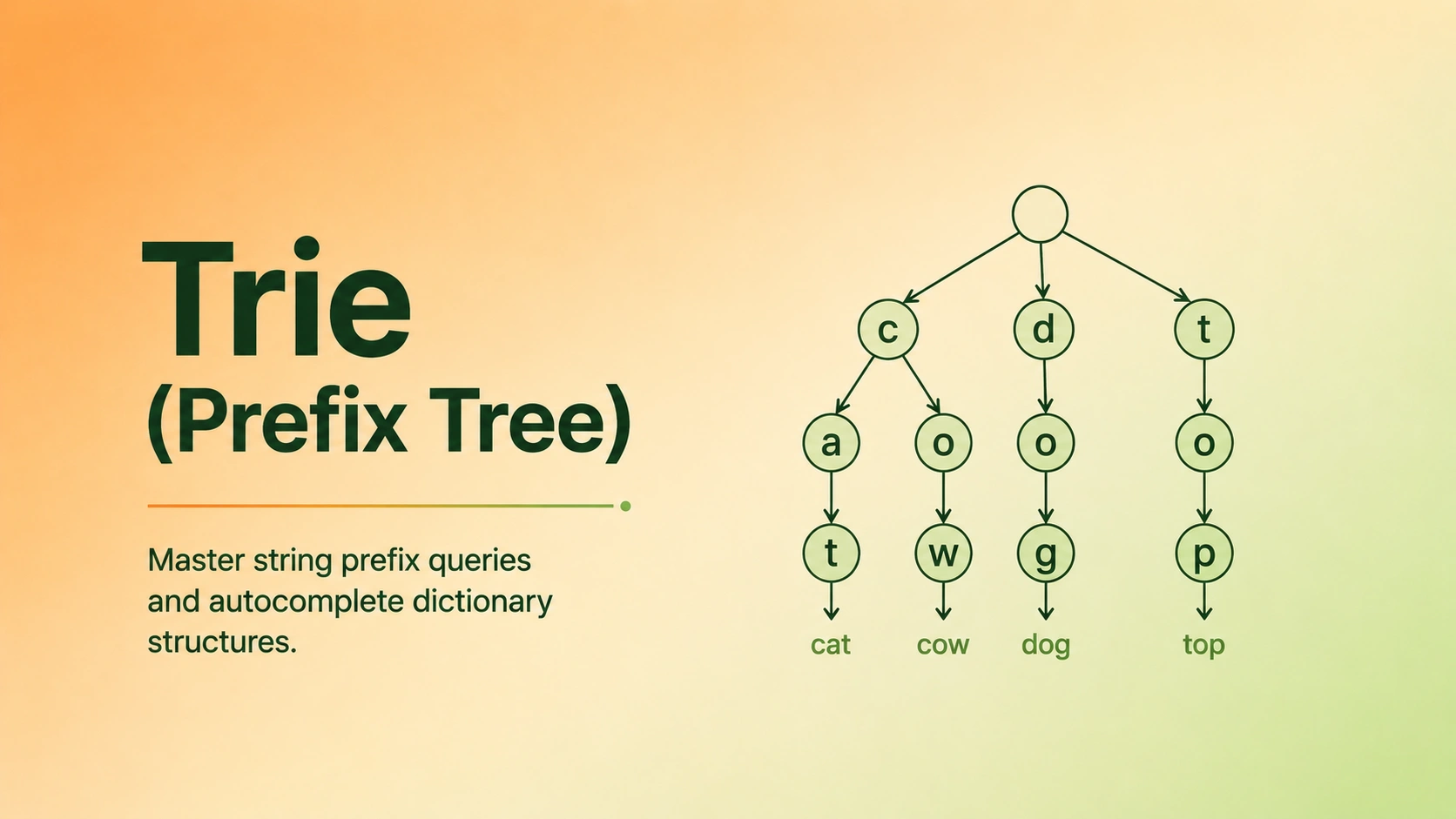
Introduction: The Alphabet Search Index
Imagine you are looking up words in a physical dictionary. If you want to find the word "apple", you do not scan from page one, reading every word linearly. Instead, you jump straight to the letter 'a'. Once you are in the 'a' section, you look for the next letter, 'p', and follow that path to find words starting with "ap". Then you look for the third letter, 'p', leading to "app", and so on.
By sharing prefixes, you quickly locate the word and ignore thousands of other unrelated words (like "banana" or "zebra").
A Trie (derived from the word retrieval, but pronounced like "try" to distinguish it from "tree") is a tree-like data structure optimized for storing and retrieving keys in a dataset of strings. It is often called a Prefix Tree because the path from the root to any node represents a prefix shared by all words descended from that node.
Analogy: The Spelling Maze
Imagine you are playing a game inside a giant Spelling Maze where you walk along letter paths to build words!
- The Entrance: The entrance to the maze is a blank starting circle called the Root.
- Spelling CAT: To spell "CAT", you walk through the 'C' door, then the 'A' door, and finally the 'T' door. When you reach the 'T' door, there's a big star sticker on the wall that says: "You spelled a real word!"
- Spelling CAB: What if you want to spell "CAB"? You start at the same 'C' and 'A' doors, but instead of turning towards 'T', you take a turn to the 'B' door, which also has a star sticker!
- Why Tries are Awesome: Notice that "CAT" and "CAB" shared the exact same 'C' and 'A' doors. You didn't have to build new doors for 'C' and 'A'! This saves a lot of space in the computer's brain.
- Smart Autocomplete: This is how the search bar on your tablet guesses what you are typing! As soon as you walk through the 'C' and 'A' doors, it looks ahead and says: "Hey, are you trying to spell CAT or CAB?"
Autocomplete & Search Engines
Tries are the secret engine behind:
- Search engine autocomplete systems: As you type "how to c...", it instantly suggests "how to code" or "how to cook".
- IP routing table lookups: Looking up the longest matching network prefix.
- Spell checkers & T9 texting: Predicting word boundaries based on character keys.
Anatomy of a Trie Node
Unlike binary trees where each node has at most two children (left and right), a Trie Node represents a character junction point and can have many children. For standard English text containing lowercase a-z, a node can have up to 26 children, each pointing to another Trie Node.
Analogy: A Room inside the Spelling Maze
What does a single room (Node) in our spelling maze look like? It has two things:
- A Bunch of Doors (Children References): Up to 26 doorways pointing to other letter rooms.
- A Star Sticker (
isEndOfWord): A true/false switch that says if spelling stops here to form a complete word. (For example, if you spell "CAR", 'R' has a star. If you keep walking to spell "CART", 'T' has a star too!).
Structural Design
A Trie Node contains:
- Children References: A collection mapping characters to child nodes. This is typically implemented in one of three ways:
- Fixed-size Array: An array of size 26 (for a-z):
children = [null] * 26where index 0 represents 'a', index 1 is 'b', etc. This offers the fastest lookup time (O(1)) but wastes memory if many slots are empty. - Hash Map: A dynamic Map mapping characters to child nodes. This is memory-efficient for sparse trees but has a small overhead.
- Binary Search Tree / Sorted List: Useful when memory is extremely constrained and character sets are large.
- Fixed-size Array: An array of size 26 (for a-z):
- End-of-word Flag (
isEndOfWord): A boolean flag indicating whether the sequence of letters from the root to this node forms a complete word. This is crucial because "app" and "apple" share the same prefix, but they are both complete words in their own right.
Visualizing a Trie containing "cat", "cab", and "car"
(Asterisk * denotes a node where isEndOfWord = true)
Node Definition
Trie vs. Hash Table: The Operational Trade-Offs
Why use a Trie when we can just throw strings into a Hash Set or Hash Map? Let's analyze the trade-offs:
| Feature | Hash Table | Trie (Prefix Tree) |
|---|---|---|
| Search (Exact Match) | O(L) (L = length of string) | O(L) |
| Space Complexity | O(N * L) (N = number of words) | O(N * L) (often much smaller due to prefix sharing) |
Prefix Matching (startsWith) | O(N * L) (must check every key) | O(L) (directly walk prefix path) |
| Sorted Traversal | Requires sorting keys | Alphabetically sorted by nature of Trie traversal |
Why Tries Excel at Prefix Search
If you want to find all words starting with "ap" in a Hash Table containing 10,000 words, you have to iterate through all 10,000 keys and check if they start with "ap". This takes O(N * L) time.
In a Trie, you walk from root -> 'a' -> 'p'. The subtree under 'p' contains exactly and only the words starting with "ap". You can retrieve or print them instantly without scanning unrelated words.
Trie Memory Optimization: Radix Trees (Compressed Tries)
One criticism of Tries is their high memory usage. If a Trie has many long words that do not share prefixes, it creates a chain of nodes with single children. For example, storing "unbelievable" without other "un-" words creates 13 distinct nodes.
To solve this, we use a Radix Tree (also known as a Compressed Trie). A Radix tree merges any node that has only one child with its parent.
Standard Trie: [Root] -> (u) -> (n) -> (b) -> (e) -> (l) -> (i) -> (e) -> (v) -> (a) -> (b) -> (l) -> (e)*
Radix Tree: [Root] -> (unbelievable)*
If we later insert "unbeaten":
Radix Tree: [Root] -> (unbeat) -> (able)*
-> (en)*
This compression dramatically reduces the node count and pointer overhead, speeding up memory access.
Trie Core Operations & Walkthroughs
A standard Trie supports four core operations: insert, search, startsWith, and delete.
Visualize character-by-character insertion, search, and prefix matching operations in a prefix tree.Trie (Prefix Tree)
1. Inserting a Word (insert)
To insert a word of length L:
- Start at the Root.
- Loop through each character in the word.
- Check if the current character exists as a child of the current node. If not, create a new child Trie Node.
- Move down to the child node.
- After processing the final character, set
isEndOfWord = true.
2. Searching for a Word (search)
To search for an exact word:
- Start at the Root.
- Loop through each character.
- If a character is not found in the children of the current node, return
falseimmediately. - Move down.
- After walking through all characters, return the value of
isEndOfWord. (If it isfalse, it means we only found a prefix, not the entire word).
3. Prefix Matching (startsWith)
To check if any word starts with a prefix:
- Walk the character path identical to the search function.
- If we reach the end of the prefix successfully without hitting any missing links, return
true. It does not matter ifisEndOfWordis true or false.
4. Deleting a Word (delete)
Deleting a word from a Trie is more complex than insertion. If we simply set isEndOfWord = false, we leave orphaned nodes in memory. If we delete nodes blindly, we might delete parts of other words (e.g. deleting "car" shouldn't destroy "cart").
We use recursion (post-order traversal):
- Walk down to the end of the word.
- Set
isEndOfWord = falseat the final character node. - As the recursion unwinds back up, we check if a node has:
- No children.
isEndOfWordis false.
- If both conditions are met, we delete the node from its parent's children map. If the node has other children or has
isEndOfWord = true(meaning it's part of another word), we stop deleting and return.
Complete Trie Implementations in 4 Languages (with Delete)
Here are the complete implementations including the recursive delete operation.
Step-by-Step Code Trace: Inserting "cat" and "cab"
Let's watch how the internal children links are created and navigated.
| Operation | Char | Current Node | Child exists? | Action | Final Node State |
|---|---|---|---|---|---|
| Insert("cat") | 'c' | Root | No | Create 'c' | Root.children['c'] = Node1 |
| 'a' | Node1 | No | Create 'a' | Node1.children['a'] = Node2 | |
| 't' | Node2 | No | Create 't' | Node2.children['t'] = Node3 | |
| Node3 | - | End of Word | Node3.isEndOfWord = true | ||
| Insert("cab") | 'c' | Root | Yes | Walk down to 'c' | Move to Node1 |
| 'a' | Node1 | Yes | Walk down to 'a' | Move to Node2 | |
| 'b' | Node2 | No | Create 'b' | Node2.children['b'] = Node4 | |
| Node4 | - | End of Word | Node4.isEndOfWord = true |
Notice that during the second insertion, the characters 'c' and 'a' were not re-created; the Trie reused existing nodes, saving memory!
Common Interview Pitfalls and Debugging Strategies
-
Losing Word Boundaries:
- Symptom:
search("app")returnstrueeven though you only inserted"apple". - Cause: You forgot to check if the target node has
isEndOfWord = true. - Fix: Ensure that exact match queries return
node.isEndOfWord, not justtrueon loop completion.
- Symptom:
-
Memory Leaks during Deletion:
- Symptom: Out of memory errors or obsolete words lingering in memory.
- Cause: Simply setting
isEndOfWord = falseleaves trailing nodes in memory. - Fix: To properly delete a word, use backtracking (DFS recursion) to clean up and delete child nodes that have empty children maps.
Practice Problems & Interactive Visualizers
Build your prefix lookup skills by practicing these standard problems on our platform:
- Implement Trie — Code insertion, lookup, and prefix testing.
- Design Add and Search Words — Support wildcard '.' character lookups.
Interactive Visualizations
Engage with these concepts dynamically. Click on any card below to launch the interactive simulator and step through the algorithm execution.
Trie (Prefix Tree)
Visualize character-by-character insertion, search, and prefix matching operations in a prefix tree.