LRU Cache — The Complete Guide to the Most Popular Cache Algorithm
Everything you need to know about the Least Recently Used cache — from intuition, implementation, and code to real-world systems and interview mastery.

Caching is one of the most underrated but crucial concepts in computer science. Whether you are loading a web page, querying a database, or rendering a mobile app, caching determines how fast your system feels. The LRU Cache — or Least Recently Used Cache — is one of the simplest yet most powerful cache replacement policies that every engineer must understand deeply.
In this article, we’ll explore the complete picture of LRU Cache: the intuition behind it, how it achieves constant-time lookups and updates, its use in real systems like Redis and operating systems, and multiple code implementations with detailed visual explanations. By the end, you’ll not only be able to code it from scratch but also design distributed caching layers with confidence.
1. Why Do We Need Caches?
Modern computing is all about speed — but memory access is hierarchical. Accessing data from CPU cache takes nanoseconds, from RAM takes microseconds, and from disk or network may take milliseconds. Caches bridge this speed gap by keeping frequently accessed data closer to the CPU or application logic.
- Reduce latency by serving hot data instantly.
- Avoid recomputation or refetching expensive results.
- Improve scalability by reducing backend load.
- Provide smoother user experiences for repeated operations.
However, since cache memory is limited, we cannot store everything. We need a smart policy to decide what stays and what gets evicted when new data arrives.
Cache Eviction Policies Overview
A cache eviction policy defines which item to remove when the cache is full. There are several well-known strategies:
- FIFO (First In, First Out): Remove the oldest inserted item first.
- Random Replacement: Evict a random item — simple but inefficient.
- LFU (Least Frequently Used): Evict the least accessed item.
- LRU (Least Recently Used): Evict the item that has not been accessed recently.
Among these, LRU strikes the best balance between efficiency, simplicity, and predictability — making it the most widely adopted algorithm for cache management.
What Is LRU Cache Exactly?
An LRU Cache is a data structure that stores a limited number of key–value pairs and removes the least recently used element when capacity is exceeded. It ensures that frequently accessed data remains quickly retrievable while discarding items that haven’t been used in a while.
- Constant-time O(1) operations for insertion, deletion, and lookup.
- Always evicts the oldest accessed item when capacity is full.
- Combines a HashMap for lookups and a Doubly Linked List for tracking recency.
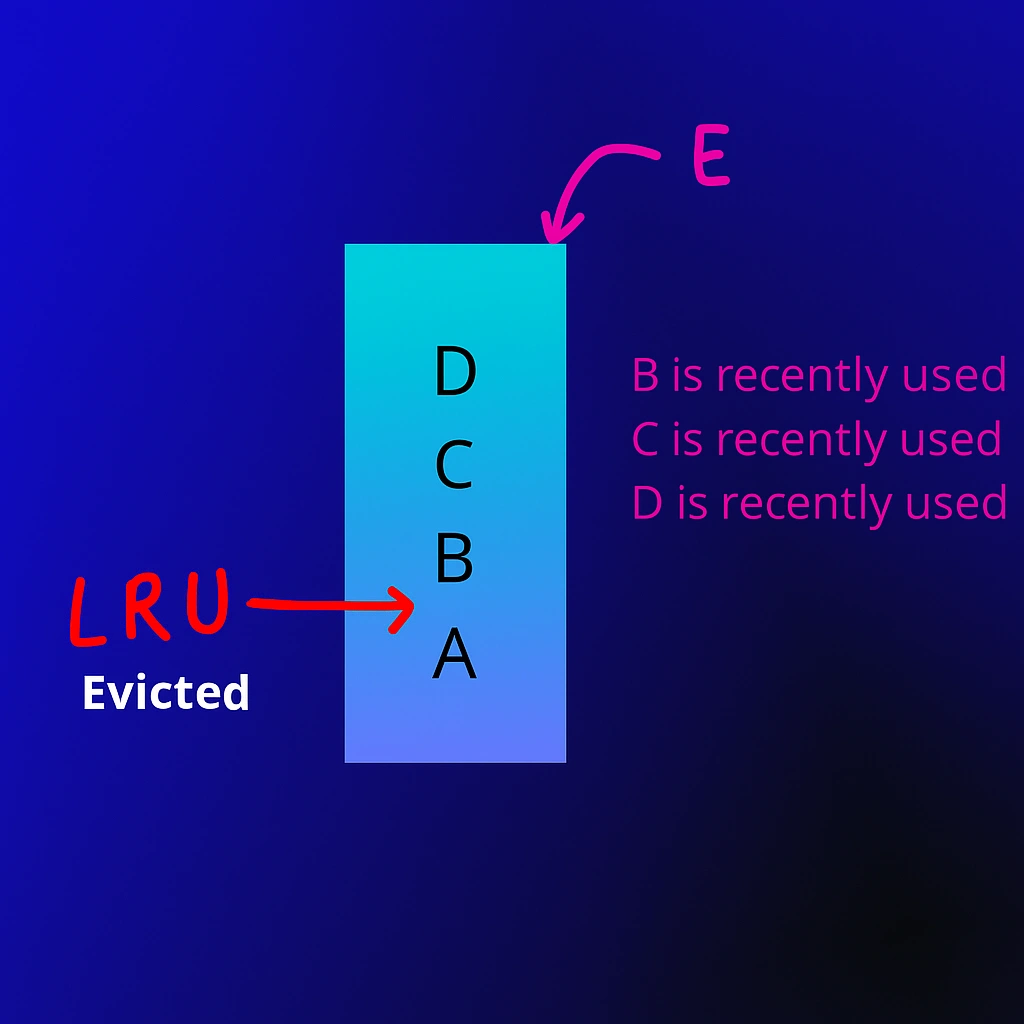
Real-World Analogy — The Study Desk Example
Imagine you have a small study desk that can hold only three books at once. When you start reading, you pick up a few books and place them on your desk. As you continue studying, you refer to some books more frequently and ignore others. If you now want to open a fourth book but the desk is full, what do you do?
Naturally, you remove the book you haven’t touched for the longest time — that’s your least recently used one. The new book replaces it. This is precisely how LRU Cache behaves with your data.
2. Internal Data Structures
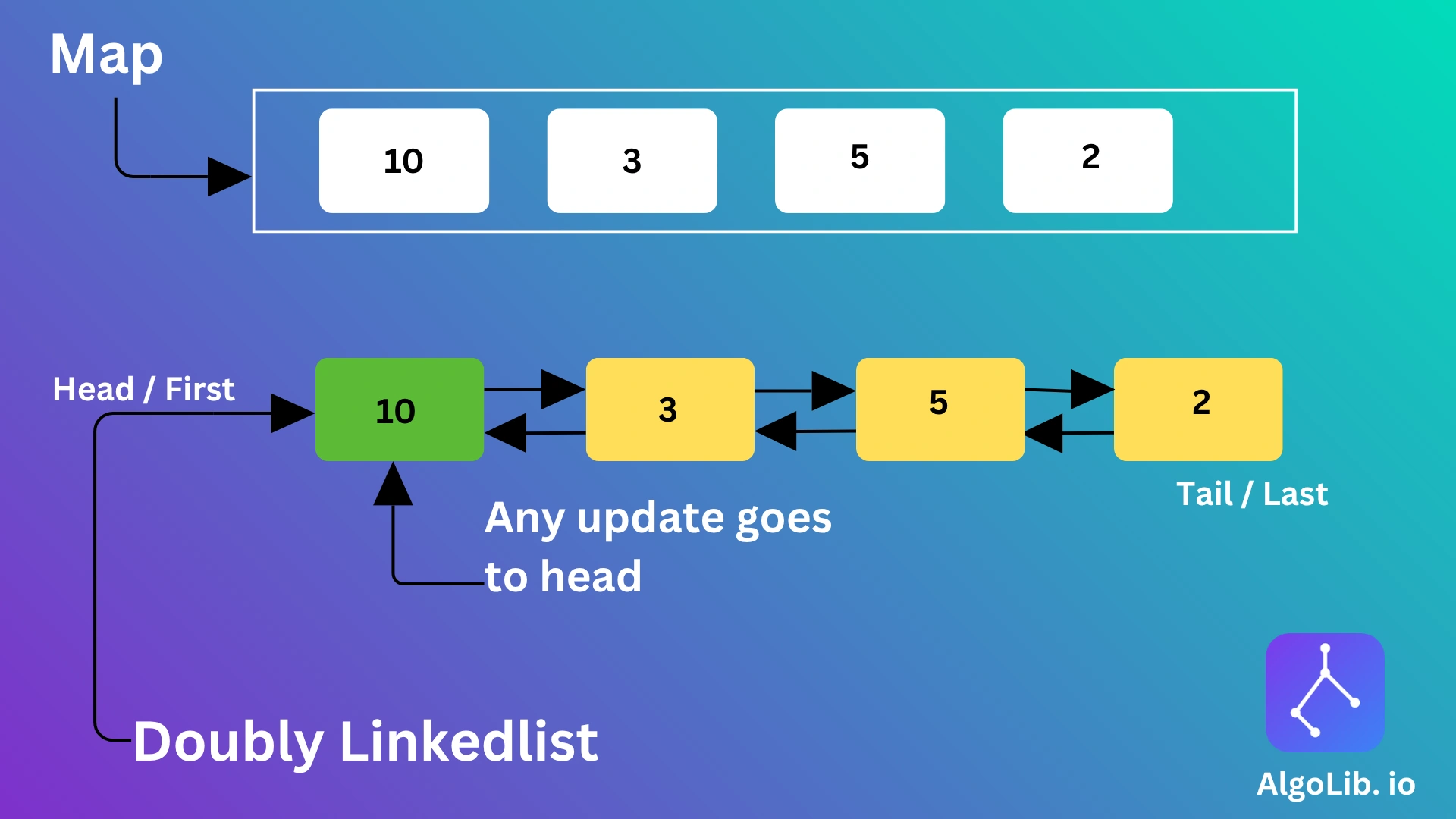
The magic of O(1) performance in LRU Cache comes from combining two data structures:
- HashMap: Stores the mapping of keys to their nodes for direct access.
- Doubly Linked List: Maintains ordering from most recently used (head) to least recently used (tail).
When you access or insert a key, the corresponding node moves to the front of the linked list. When capacity is full, the node at the tail (least recently used) is removed.
Core Operations Explained
- get(key): Retrieve value if it exists. Move the node to the head because it was just used.
- put(key, value): Insert or update key–value pair. If capacity exceeds, remove the tail node.
Both operations take O(1) time because the HashMap provides constant-time lookups and the linked list provides constant-time removals and insertions at head or tail.
3. Step-By-Step Example
Let’s simulate a cache with capacity = 3 and sequence of operations:
- put(1, A) → Cache: [1:A]
- put(2, B) → Cache: [2:B, 1:A]
- put(3, C) → Cache: [3:C, 2:B, 1:A]
- get(2) → Cache: [2:B, 3:C, 1:A]
- put(4, D) → Evict least recently used (1:A) → Cache: [4:D, 2:B, 3:C]
Notice how each access or insertion updates the recency order, keeping the most recent element at the front.
Implementation From Scratch (Python)
1class Node:2def __init__(self, key, value):3self.key = key4self.value = value5self.prev = None6self.next = None7class LRUCache:9def __init__(self, capacity: int):10self.capacity = capacity11self.cache = {}12self.head = Node(0, 0)13self.tail = Node(0, 0)14self.head.next = self.tail15self.tail.prev = self.head16def _remove(self, node):18prev, nxt = node.prev, node.next19prev.next = nxt20nxt.prev = prev21def _add(self, node):23node.prev = self.head24node.next = self.head.next25self.head.next.prev = node26self.head.next = node27def get(self, key):29if key not in self.cache:30return -131node = self.cache[key]32self._remove(node)33self._add(node)34return node.value35def put(self, key, value):37if key in self.cache:38self._remove(self.cache[key])39node = Node(key, value)40self._add(node)41self.cache[key] = node42if len(self.cache) > self.capacity:43lru = self.tail.prev44self._remove(lru)45del self.cache[lru.key]46
Time & Space Complexity
- get() → O(1)
- put() → O(1)
- Space Complexity → O(capacity)
Implementation in JavaScript
1class LRUCache {2constructor(capacity) {3this.capacity = capacity;4this.cache = new Map();5}6get(key) {8if (!this.cache.has(key)) return -1;9const value = this.cache.get(key);10this.cache.delete(key);11this.cache.set(key, value);12return value;13}14put(key, value) {16if (this.cache.has(key)) this.cache.delete(key);17this.cache.set(key, value);18if (this.cache.size > this.capacity) {19const firstKey = this.cache.keys().next().value;20this.cache.delete(firstKey);21}22}23}24
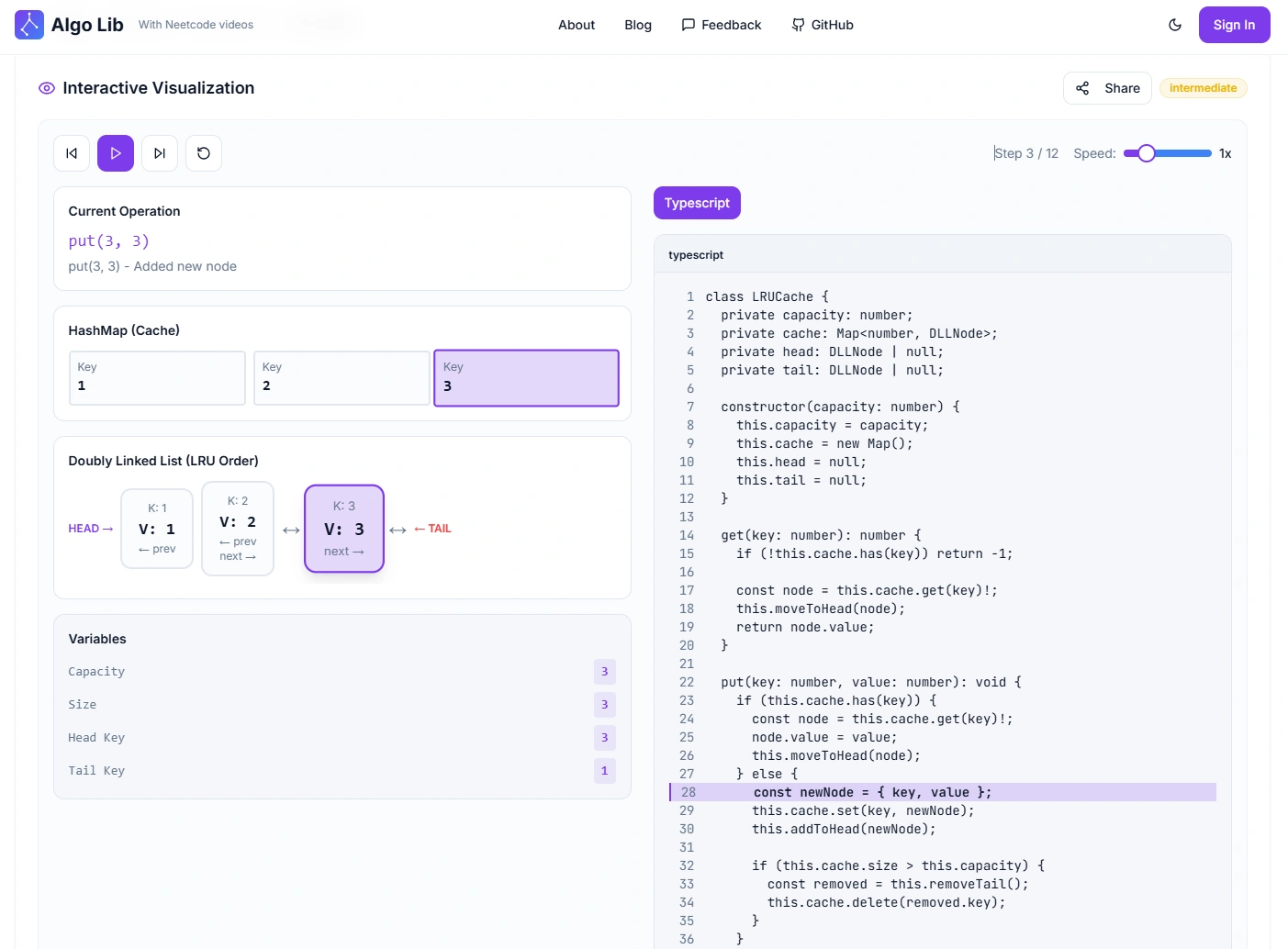
4. Visualization with Rulcode.com
Visualizing the LRU cache makes its mechanism intuitive. In Rulcode.com’s animation:
- Each node represents a key–value pair connected via arrows.
- When get() is called, the accessed node moves to the left (most recent).
- When put() inserts a new key, it appears on the left, and if full, the rightmost node fades out (evicted).
- The animation highlights constant-time operations clearly, showing why the linked list + hashmap design is optimal.
Variations & Alternatives
- MRU (Most Recently Used): Evicts the most recently accessed item — opposite of LRU.
- LFU (Least Frequently Used): Tracks frequency instead of recency — used in databases.
- 2Q Cache: Maintains two queues (new and frequent) for better adaptation.
- ARC (Adaptive Replacement Cache): Hybrid of LRU and LFU used in enterprise file systems like ZFS.
Real-World Applications
- CPU Cache: Decides which memory blocks to evict from fast L1/L2 caches.
- Web Browsers: Remove old pages or images as new ones load.
- Operating Systems: Virtual memory page replacement.
- Databases: Query and result caching (MySQL, PostgreSQL).
- Redis: Uses LRU-based eviction in its "maxmemory-policy" setting.
5. Common Interview Questions
- Implement an LRU Cache from scratch.
- How do you achieve O(1) get() and put()?
- Explain difference between LRU and LFU.
- How would you scale an LRU cache across multiple servers?
- What happens in a distributed caching system when eviction occurs?
6. LRU in System Design
In system design interviews, caching is critical. LRU fits well in any tier where limited high-speed memory must store a subset of data. Examples:
- 📦 CDN edge servers caching recently requested static assets.
- 🧰 Microservice data caching layer (in-memory LRU).
- ⚙️ Database read-through cache for hot queries.
- 📱 Mobile applications caching images or API responses locally.
Common Pitfalls in Implementation
- Forgetting to move accessed nodes to head — breaks recency tracking.
- Not removing tail node on overflow — leads to incorrect capacity behavior.
- Removing from HashMap but not from list (or vice versa).
- Using singly linked list — O(n) removal instead of O(1).
- Overcomplicating structure when capacity = 0.
7. Beyond the Basics — Distributed LRU Cache
In large-scale systems, a single LRU cache instance may not be enough. Distributed caches partition data across nodes while maintaining local LRU policies. Frameworks like Redis Cluster or Memcached use consistent hashing and per-node eviction. Designing such systems involves trade-offs between consistency, load balancing, and latency.
8. Performance Considerations
- LRU is optimal when recent access predicts future access (temporal locality).
- In purely random workloads, it may behave close to FIFO.
- For I/O-intensive systems, LRU ensures that hot data remains in memory while stale data gets flushed.
- Hybrid policies (like LRU + TTL) can combine temporal freshness with recency tracking.
9. Code Extensions — Thread-Safe LRU
In multi-threaded environments, access to the cache must be synchronized. In Python, you can use threading.Lock() or in JavaScript, an atomic design pattern to ensure thread safety. In Java, you can wrap LRU logic with Collections.synchronizedMap() or use ConcurrentLinkedHashMap.
10. Why Visual Learning Matters
Understanding LRU conceptually is good, but seeing it in action cements the knowledge. Visual tools like Rulcode.com allow you to interact with algorithms — pausing, rewinding, and exploring step-by-step execution. Watching nodes move as operations occur gives you the spatial intuition you can recall instantly in interviews.
Final Thoughts
The LRU Cache exemplifies elegant algorithmic engineering — achieving perfect balance between recency, performance, and memory usage. It’s a cornerstone of real-world system design, and mastering it will sharpen your understanding of how software performance scales. Once you truly internalize the pattern, you’ll start recognizing LRU-like mechanisms everywhere — in browsers, in APIs, even in your own code.
About the Author: Rulcode Team
The Rulcode Team is passionate about computer science, competitive coding, and interactive education. We build tools and write guides to help developers master complex algorithms and ace technical interviews.